Live
- Apple Speech
- Deepgram Nova-3 + Flux
- Cartesia Ink-2
- Gladia Solaria-1
- AssemblyAI Universal-3 Pro
- Soniox Real-time v5
- ElevenLabs Scribe v2
- Modulate Velma-2
- OpenAI GPT-4o Transcribe
Fast, private dictation for Mac, iPhone, and iPad. Run speech models locally, stream with your own provider keys, and paste polished text anywhere.
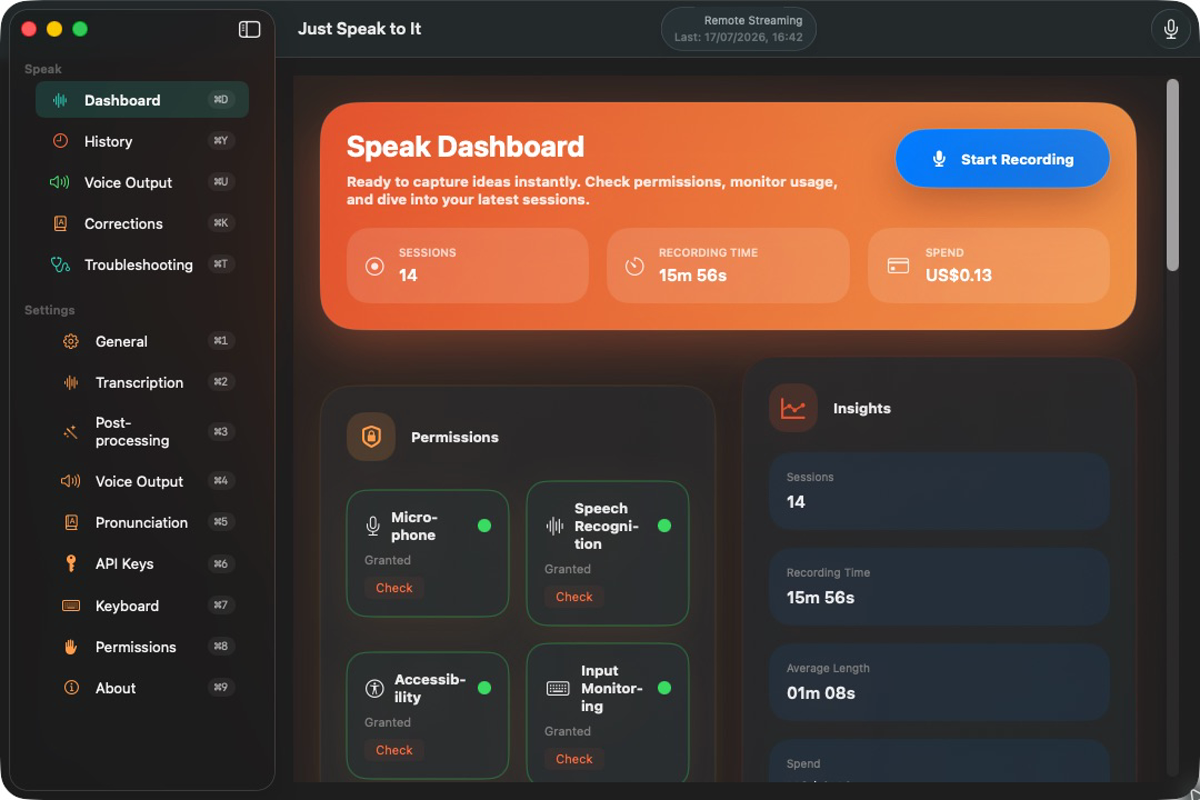
Start on-device, switch to specialist streaming, or bring a long-form recording. Just Speak to It keeps the choice visible instead of locking you into one provider.
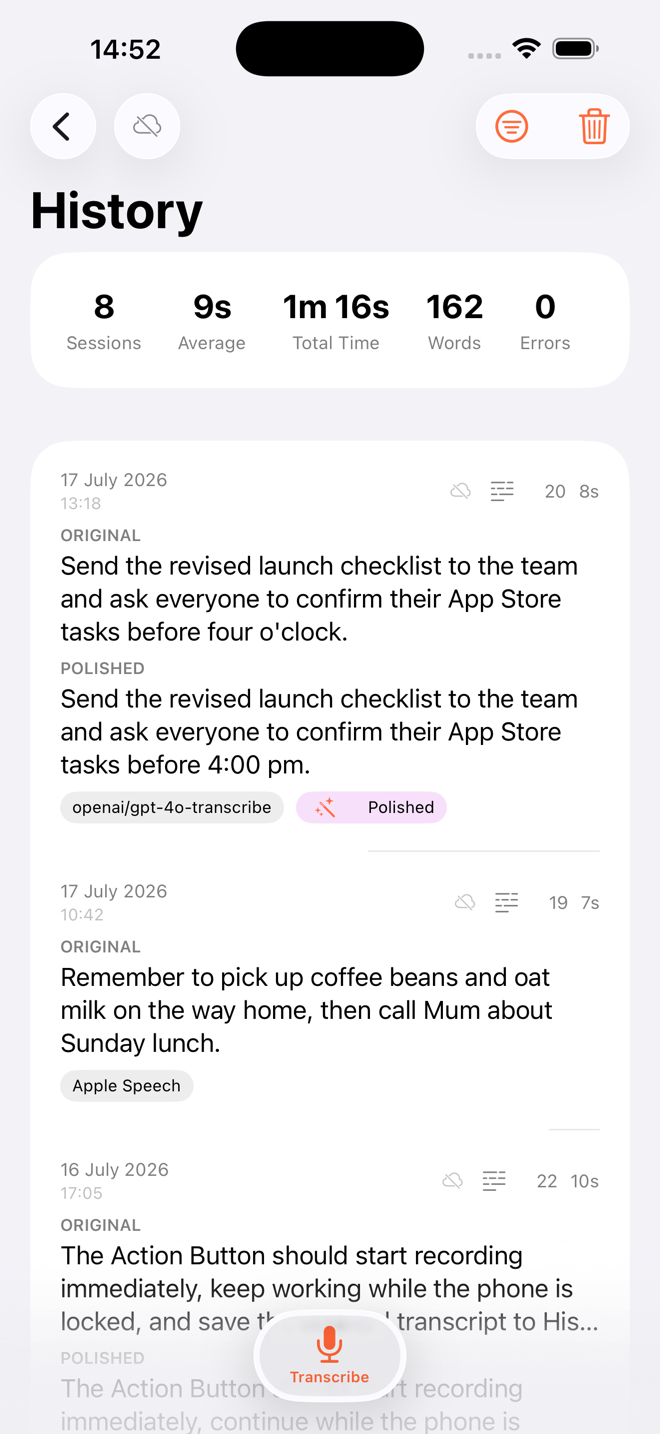
One clean sequence from intention to useful text. The clipboard changes only when the final transcript is ready.
Start from your keyboard, Action Button, Shortcuts, or the app.
Watch live words arrive while you speak.
Copy or paste the final text only when it is ready.
Fast updates and full access to local model support.
Download for Mac →Sandboxed store distribution for a familiar install and update path.
Submitted for App ReviewAction Button, Shortcuts, Live Activity, and iCloud history.
Submitted for App ReviewBring Your Own Key (BYOK) for supported providers.
Your audio and text stay on your device with local models.
Use the cloud only when you choose to.
I build focused tools that respect your attention and your data. Just Speak to It is the dictation app I’ve always wanted.
Read the blog at mitchelmore.uk →Other project